图像识别的最新进展
1998年,MNIST被引入的那一年,一个最先进的工作站花数周训练得到的精确度,还不及我们可以使用GPU训练不到一个小时的结果。因此,MNIST不再是一个挑战现有技术极限的问题;相反,训练的速度意味着这是一个有利于教学和学习的问题。与此同时,研究的重点已经转移,而现代工作涉及到更具有挑战性的图像识别问题。在这一节,我短暂描绘一些在用神经网络识别图像方面最近的成果。
这一节和书中大部分章节有所不同。贯穿全书,我把重点放在了可能回味深远的想法上——比如反向传播、正则化和卷积网络。我试着在写作时避免那些当前很流行,但长期来看结果未知的东西。在科学领域,这样的结果往往是昙花一现,并没有持久的影响。对此,持怀疑态度的人可能会说:“好吧,最近在图像识别方面的进步当然是这样昙花一现的例子喽?再过两三看就会被超越。那么,这些结果肯定只有那些角逐在绝对前沿的专家会感兴趣吧?为什么还要兴师动众的去讨论它呢?”
这种怀疑的观点是正确的,近来论文上一些出彩的细节将被逐渐淡化。照这样说,过去几年通过使用深度网络来攻克极其困难的图像识别任务,已经取得了惊人的进步。想象一下,2100年的一位科学历史学家写关于计算机视觉的文章。他们将把2011年到2015年(可能还有几年)作为由深度卷积网络主导的一个巨大突破。这并不意味着在2100年仍将使用深度卷积网络,更不说诸如像dropout、修正线性单元等这些细节思想。但它确实意味着,现在的观念正在发生一个重要的转变。这有点像观察原子的发现,或抗生素的发明:一种具有历史意义的发明和发现。所以我们不会去深入细节中,但值得去了解那些当前在做的让你兴奋的发现。
2012年的LRMD论文:让我们从一篇2012年来自斯坦福大学和谷歌研究小组的论文【Building high-level features using large scale unsupervised learning, 作者 Quoc Le, Marc'Aurelio Ranzato, Rajat Monga, Matthieu Devin, Kai Chen, Greg Corrado, Jeff Dean, 和 Andrew Ng (2012). 注意论文中用的网络架构细节上和我们学过的深度卷积网络的网络上有些不同。然而一般来说,LRMD是基于许多相似的想法】。我把这篇文章称为LRMD,用了前四位作者最后一个名字。LRMD使用一个神经网络分类来自ImageNet上的图片,这是一个非常具有挑战性的图像识别问题。他们使用的2011年ImageNet数据包含了2万个类别1600万张彩色图像。这些图片是从开放的网络上爬下来的,并通过来自Amazon的Mechanical Turk服务的工作者进行分类。这是一些ImageNet上的图片【这些来自2014数据集,与2011年有所不同。尽管这样,从质量上讲这些数据是极其相似的。关于ImageNet的细节可以看原生的ImageNet论文: ImageNet: a large-scale hierarchical image database,作者Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, 和 Li Fei-Fei (2009).】:




这些分别是属于以下类别 beading plane, brown root rot fungus, 热牛奶和常见的蛔虫。如果你想挑战一下,我支持你去看一下ImageNet的手用工具清单,里面区分了beading planes, block planes, chamfer planes和几十种其他类型的刨子。我不知道你是怎样,反正我是不能确信将所有这些工具类型区分清楚。这显然是比MNIST更具有挑战的图像识别任务!LRMD的网络针对ImageNet图像分类得到了15.8%这样一个可敬的准确率。那可能听上去不是一个傲人的成绩,但相对于之前最好结果9.3%的准确率来讲是一个巨大的提升。这一跳跃表明,神经网络可能提供了一种强大的方法来处理非常具有挑战性的图像识别任务,如ImageNet。
2012年的KSH论文:LRMD之后的是一篇2012年Krizhevsky, Sutskever 和 Hinton(KSH)的论文【ImageNet classification with deep convolutional neural networks, 作者 Alex Krizhevsky, Ilya Sutskever, 和 Geoffrey E. Hinton (2012).】。KSH用ImageNet数据下一个有限的子集训练并测试了一个深度卷积神经网络。他们使用的这个子集来自一个流行的机器学习竞赛——ImageNet大规模视觉识别挑战赛(ILSVRC)。使用竞赛数据集是一种和其他领先技术做比较的好方法。ILSVRC-2012训练集包含了从1,000个类型中抽取了大约1.2亿张ImageNet图像。其验证和测试数据集分别包含了从1,000个相同类型中抽取的50,000和150,000张图片。
跑ILSVRC竞赛的一个不同是许多ImageNet图片包含多个目标。假设一张图片显示一只拉布拉多猎犬在追逐一个足球。那这张图片所谓的“正确”ImageNet分类可能是像一只拉布拉多猎犬。如果一个算法给图片打上足球的标签的话应该受到惩罚吗?因为这种模糊性,如果正确的ImageNet分类是在一个算法认为最有可能的5个分类中,那这个算法就被认为是正确的。通过这样的Top5规则,KSH的深度卷积网络达到了84.7%的准确率,远远好于第二好比赛算法的73.8%的准确率。用更严格的标准,给定标签要完全正确的话,KSH网络的准确率是63.3%。
值得暂时描述一下KSH的网络,因为它激发了许多后续工作。我们将看到它和我们这一章之前训练的网络很接近,虽然它更复杂。KSH用一个深度卷积演绎网络,在2个GPU上训练。用2个GPU是因为他们用的GPU型号(一个NVIDIA GeForce GTX 580)没有足够显存来存储他们的整个网络。所以他们将网络分成了两部分到2个GPU上。
KSH网络有7层的隐含神经元。开始5个隐含层是卷积层(一些带有最大池化 ),后面的2层是全连接层。输出层是一个有1,000个单元的softmax层,对应1,000个图片类别。这是从KSH论文中摘出的网络草图【感谢Ilya Sutskever】。细节部分的解释在下面。注意许多层被分成2部分,对应2个GPU。
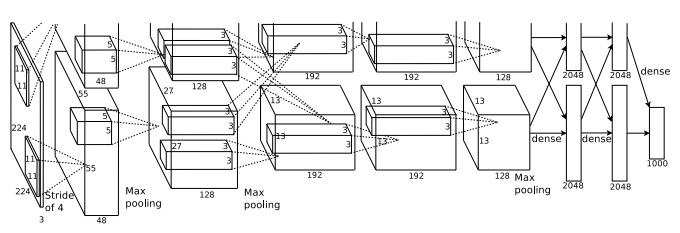
输入层包含个神经元,代表一张张图片的RGB值。回想一下,正如前面提到的,ImageNet包含不同分辨率的图像。这提出了一个问题,因为一个网络的输入层通常是固定大小的。KSH解决这个问题是通过缩放每张图片,让其最短边的长度为256。然后他们在缩放后图片的中心处裁剪出一个的区域。最终,KSH从的图片上随机提取的子图(和水平方向上的倒影)。他们是将这种随机裁剪作为扩充训练数据的方式,来减少过拟合。这对像KSH这样的大型网络特别好用。这些被用来作为网络的输入。大部分情况下裁剪过的图片仍能包含未裁剪图片的主要目标。
来看一下KSH网络的隐含层,第一个隐含层是一个卷积层,带有一个最大池化的步骤。它用的感受野大小是,步幅长度是4像素。共有96个特征映射。特征映射被分成两组,每个有48个,第一组48个特征映射驻留在一个GPU上,第二组48个在另一个GPU上。在这和下一层的最大池化用的区域,但这个池化区域是允许重叠的,并且相距只有2像素。
第二个隐含层也是一个卷积层,带有一个最大池化的步骤。用的感受野,共有256个特征映射,分到每CPU上128个。注意特征映射只用48个输入通道,不是前一层全部的96个输出(通常情况是用全部的)。这是因为每个特征只用相同的GPU上的输入。从这个意义上讲,虽然网络脱离了我们本章之前描述的卷积架构,但很明显其基本思想仍然是相同的。
第三、四、五个隐含层是卷积层,但不像前面的几层,它们没有最大池化。它们各自的参数是:(3)384个特征映射,用的感受野和256个输入通道;(4)384个特征映射,用的感受野和192个输入通道;(5)256个特征映射,用的感受野和256个输入通道。注意第三层涉及了一些inter-GPU间的通信(像图示上描述的),目的是能让特征映射用全面的256个输入通道。
第六和七个隐含层是全连接层,每层有4,096个神经元。
输出层是一个1,000个单元的softmax层。
KSH网络用了许多技术。KSH用修正线性单元替代了sigmoid或tanh激活函数,显著的提升了训练速度。KSH的网络大约有6千万个学习参数,这就导致即使有大的训练集,也很容易过拟合。为了克服这一点,他们用我们上面讨论过的随机裁剪策略来扩充训练集。他们也用了l2正则和dropout进一步解决过拟合的问题。网络训练用的是基于动量的最小批次随机梯度下降法。
这是KSH论文中众多核心思想的一个概览。我省略了一些细节,你可以在论文中看到。你也可以看下Alex Krizhevsky的cuda-convnet(和successors),包含了许多思想的代码实现。一个基于Theano的实现已经开发出来【Theano-based large-scale visual recognition with multiple GPUs, 作者 Weiguang Ding, Ruoyan Wang, Fei Mao, 和 Graham Taylor (2014).】,代码在这里。代码与本章中所开发的代码类似,尽管多个GPU的使用让事情变得复杂了一些。Caffe神经网络框架也包含了不念旧恶KSH网络的版本,可以看他们的Model Zoo来获取更多细节。
2014年ILSVRC竞赛:从2012年开始,发展一直很迅速。看下2014 ILSVRC竞赛。在2012年,它包含一个有1,000个分类的1.2亿张图片的训练集,价值函数是看前5个预测是否包含正确的类别。获胜队主要是在Google【Going deeper with convolutions, 作者 Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, 和 Andrew Rabinovich (2014).】,用的一个深度卷积网络,有22层的神经元。他们称他们的网络为 GoogLeNet,向LeNet-5致敬。GoogLeNet的top-5准确率为93.33%,相对于2013的获胜者(Clarifai,88.3%)和2012年获胜者(KSH,84.7%)是一个巨大的提升。
GoogLeNet的93.33%的准确率好到什么程度呢?2014年一个研究队伍写了一个关于ILSVRC竞赛的调查论文【ImageNet large scale visual recognition challenge, 作者 Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, 和 Li Fei-Fei (2014).】。他们解决的问题中有一个是人类在ILSVRC中做的怎样。为了实现这个目标,他们构建一个让人类分类ILSVRC图片的系统。作为作者之一,Andrej Karpathy在一篇教育性博客中解释到,让人类达到GoogLeNet的性能有很多麻烦:
...给图片打标签的任务中,最大的挑战是快速从的1000个类别中挑5个,甚至对一些在实验室工作研究ILSVRC和其分类的朋友来说。首先我们想到的是把它放到[Amazon Mechanical Turk]上。然后我们想我们应该招一些带薪大学生。然后,我在实验室里组织了一个标签小组,强调标签的效果只能在(专门的标签)中。然后我开发了一个修改过的接口,用GoogLeNet预测把类别的数量从1000压缩到只有100个。它还是很难——人们还是会丢一些类别,错误率达到的范围在13-15%。最后我意识到能与GoogLeNet有所竞争的地方,我们是更高效的,如果我坐下来,经历痛苦漫长的训练过程,随后仔细注释的过程...打标签的效率是每分钟一个,但会随时间下降...一些图像很容易辨认,同时有些图片(比如那些详细品种的狗、鸟或猴子)要好几分钟来集中精神来处理。我在辨识狗的品种上变的很在行...在我处理的图片样本中,GoogLeNet的分类错误率是6.8%...我自己的最后的错误率是5.1%,大约要好1.7%。
换句话说,一名专业人士,苦心修炼,经过极大努力才勉强击败了深度神经网络。实事上,Karpathy报导了第二个人类专家,在少一些的图片样本上训练,只能达到12.0%的top-5错误率,明显低于GoogLeNet的性能。大约有一半的错误是由于专家“没有发现而将地面作为一个真正的标签”。
这些结果很让人惊讶。因这项工作,多个团队报告说系统的top-5错误率确实要优于5.1%。这有时被媒体报导为系统已经有比人类还要好的视觉能力。虽然结果很令人兴奋,但有许多注意的事项,让其误认为系统已经比人类的视觉好了。在许多方面,ILSVRC挑战是一个相当有限的问题——开放式的web爬虫并不代表需要在应用中发现的图片!(a crawl of the open web is not necessarily representative of images found in applications! 这一句不会翻,瞎翻的-_-!)当然,top-5规则也太虚了。我们在解决图像识别或更宽泛的计算机图像问题上,还有很长一段路要走。尽管如此,在短短几年之内能在这样一个富有挑战的问题上,有这样长足的进步还是很令人鼓舞的。
其他活动:我们集中在ImageNet上,但用神经网络网络来做图像识别,还有数量可观的其它活动。让我简短的说一点最近有越的结果,来对一些当前的成果有一些认识。
Google的一个团队给出了一组令人鼓舞的实质性结果,他们将深度卷积网络应用到在Google的街景图像中识别街道号的问题上【Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks, 作者 Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, 和 Vinay Shet (2013).】。在他们的论文里,他们报告说检测并自动记录近1亿个街道号的准确率和一个人类操作员差不多。这个系统很快:在不到一小时的时间里,他们的系统就把法国所有街道上的街景图片都记录下来了!他们说:“有了这个新的数据集显著的提升了Google Map在多个国家的地理编码质量,特别是那些还没有其它好的地理编码资源。”并且他们继而提出了更宽泛的观点:“我们相信这个模型已经解决了针对许多应用针对短序列[字符]的[光学字符识别]问题。”
我可能给出的印象是,所有都是一种令人鼓舞的结果。当然,一些最有意思的工作报告都是基于我们还不理解的东西。例如,一篇2013年的论文【Intriguing properties of neural networks, 作者 Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, 和 Rob Fergus (2013)】展示出深度网络可能会受到实际上不可见斑点的影响。考虑下面几行图片。左边的是他们的网络可以正确分类的ImageNet图像。右边是一张有些许扰动的图片(中间的是扰动),网络的分类结果就不正确了。作者发现了有一种针对所有样本图像,不是仅对特殊几个的“对抗”图像。

这是一个让人不安的结果。论文用的网络是基于和KSH网络相同的代码——也就是说,这种类型的网络正在被广泛使用。虽然这样的神经网络计算函数在原则上是连续的,但像这样的结果表明在实践中它们很可能会计算出几乎不连续的函数。更糟糕的是,它们会以违反我们直觉的方式不连续地表现出合理的行为。这让人很忧虑。此外,还不能很好理解是什么导致了这种不连续:是损失函数中一些东西吗?用的激活函数?网络的架构?别的什么东西?我们还不知道。
现在这些结果还没有像听起来那么糟糕。虽然这种对抗性的图像很常见,但在实际应用中也是不相像的。正如文章所言:
负面抵抗的存在似乎与网络所达到的高泛化性能产生了矛盾。确实,如果网络可以泛化的很好的话,那它怎么会被这些和正规样本几乎一样的负面抵抗给弄糊涂呢?解释是负面抵抗出现的概率是极低的,导致在测试集从未(或很少)被观察到,所以几乎在每个测试用例都能发现。
然而,令人痛心的是,我们对神经网络的理解如此之差,以至于应该是最近才发现这样的结果。当然,这些结果的一个主要好处是它们激发出许多后续工作。例如,一篇最近的论文【Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images, 作者 Anh Nguyen, Jason Yosinski, 和 Jeff Clune (2014).】展示了给出一个训练好的网络,可以生成一些人类看来是白噪声,但网络却高度相信其属于一个已知分类。这从另一方面演示了,我们在理解神经网络和用它们来做图像识别方面还有很长一段路要走。
尽管有这样的结果,总体情况还是令人鼓舞的。我们看到在像ImageNet这样极其困难的比赛上进展神速。我们也看到了在解决像识别街景里的街道号这样的现实世界问题中进展飞快。但是虽然让人很受鼓舞,但只看比赛或即使是现实应用上的进步还是不够的。还有一些我们不怎么理解的基本现象,比如对抗图像的存在。当这样的基本问题仍被发现(更不用说解决),说我们几乎解决了图像识别问题还言之过早。同时这样的问题也进一步激发了未来的工作。