反向传播背后的四个基本等式
反向传播是关于理解怎样改变权重和偏移量来改变网络里的成本函数的。到最后就是求偏导数和。但为了计算它们,首先介绍一个中间量,表示层里第个神经元的误差。
反向传播将给出计算误差的步骤,然后将关联到和。
为了理解误差是怎样定义出来的,想象在神经网络里有一个小坏蛋:

小坏蛋坐在层第个神经元上。当神经元的输入值进来的时候,小坏蛋就干扰神经元的操作。它在神经元的权重输入上加一了点改变,所以神经元的输出就变成了。这个改变传播到网络的后面几层,最终造成总成本变为。
现在,这个小坏蛋是一个好的小精灵,它尝试着帮你改善成本,也就是说,它们尝试去找一个来让成本更小。假设的值很大(无论是正数还是负数)。然后小精灵能够通过选择和相同符号的,来让成本减小一点点。相对来说,如果接近0,那么小精灵就很难通过干扰权重输入来改善成本。对于小精灵来说,这个神经元已经非常接近最佳值了【当然,这只有在微调的情况下。下面我们将看到小精灵被迫使做出这样的微调】。因此在直觉上,可以衡量神经元的误差。
出于这个故事,我们定义层里神经元的误差为
按之前的惯例,使用表示与层相关误差的向量。反向传播将给我们一种计算每一层的方式,然后将这些误差关联到我们真正关心的和上。
你可能会疑惑什么小精灵要改变权重输入。诚然想象中小精灵改变激活输出值更加自然,这样就可以用衡量误差。实际上,如果你这样做的话会和下面讨论的很相似。但反向传播的代数形式会复杂一点。所以我们将仍然使用来衡量误差【在像MNIST的分类问题里,术语"误差"有时表示分类失败率。例如,如果神经网络正确分类数字的正确率是96.0%,那么误差就是4.0%。显然,这和我们的向量的意思相差甚远。实际上,在任何案例中,你都不会在其意思上有所疑惑。】。
行动计划: 反向传播基本上是围绕着四个基本等式。这些等式可以让我们计算误差和成本函数的梯度。下面将展示这四个等式。但要警告一点:请不要期望一下子就消化掉这些等式。这种期望引来的是失望。实际上,反向传播等式蕴含很多知识,理解它们需要很长的时间和耐心,去循序渐进地钻研这些等式。幸运的是多数情况下这样做会收获更多的知识。所以这一部分的讨论仅仅是一个开始,帮你踏上理解这些等式的旅程。
下面是旅程的预览,我们将在本章的后面做更深入的研究;我将给出这些等式简短的证明,用来表达它们的正确性;我们将把这些等式重新写成伪代码的算法,然后看看这些伪代码怎么实现成真正可用的Python代码;本章的最后一节,我们将做一些直观的图像来展示反向传播等式的含义,并讨论一下怎样才能有人碰巧发现它们。延着这个方向,我们将再温习一遍这四个等式,这样可以加深对这些等式的理解,你会发现它们看起来挺舒服的,甚至是,很漂亮很自然。
求输出层误差等式:的组成部分为
这个一个非常自然的等式。右边的第一项,只是用来衡量成本函数相对于第个激活输出值变化的快慢。举例来说,如果不是很依赖特定神经元的输出,那将跟我们期望的一样,很小。右边第二项,表示激活函数随变化的快慢。
需要注意的是(BP1)里的所有项都是很容易计算的。实际上,我们在计算网络行为的时候就将算出来了,同时只是在上面增加了一点额外的计算。当然,的准确形式依赖于成本的具体形式。尽管如此,提供的成本函数都是已知的,计算问题不大。例如,如果使用的是二次成本函数,那,它看上去就很容易计算。
等式(BP1)是每一项的表达式。它很完美,但对于反向传播来说不是我们想要的基于矩阵的形式。尽管这样,很容易将其重新写成基于矩阵的形式,就像
这里是偏导数所有部分的向量形式。你可以将看成是相对于激活输出值的变化率。等式(BP1a)和(BP1)很容易看出来是等价的,出于这个原因,从现在开始将用(BP1)来表示上面两个等式。做一个例子,在使用二次成本函数的情况下,我们有,所以(BP1)的全矩阵形式就变为
如你所见,表达式的每一项都是很好的向量形式,可以用像Numpy这样的库很容易的计算出来。
用下层误差求误差的等式:形如
这里的是层权重矩阵的转置。这个等式看上去很复杂,但每一项都很好解释。假设已知层的误差。乘上权重的转置矩阵,可以直观的当成是通过网络反向转移了误差,让我们可以在层的输出上测量它的误差。然后乘上Hadamard积。这通过层里的激活函数反向转移了误差,让我们可以求出层权重输入的误差。
通过结合(BP2)和(BP1),我们可以求网络里的任意一层的误差。通过使用(BP1)求开始,然后用等式(BP2)求,再用等式(BP2)求,以此类推,一直求出网络的所有层。
求网络中对于任意偏移量的成本变化率等式:形如:
也就是说,误差和的变化率是相同的。这是个利好的消息,因为(BP1)和(BP2)已经告诉我们怎样计算了。可以简写成
它可以理解成神经元的和偏移量有相同的估值。
针对网络中任意权重的成本变化量等式:形如:
它告诉我们如果用已知的和计算偏导数。这个等式可以被重写成轻索引的符号形式
它可以理解为,是权重为时神经元输入的激活值,是权重为时神经元输出的误差。放大来看权重和与其相连的两个神经元,可以描述成:
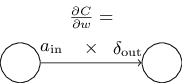
等式(32)的一个非常好的结果是当激活值很小时,,梯度项也会趋于很小。在这种情况下,我们称之为权重学习缓慢,意味着在梯度下降过程中变化很小。换句话说,(BP4)的一个推论是权重在低激活输出值的神经元里学习缓慢。
沿着这个思路,从(BP1)-(BP4)中可以观察到一些别的性质。先来看一下输出层。考虑(BP1)中的公式。回顾上一章中Sigmoid函数的图形,当接近0或1时,函数变得非常平坦。这时。所以教训就是,如果输出神经元的激活值较低()或较高(),最后一层里的权重将学习得非常慢。这种情况下通常说输出神经元已经饱和了(saturated),结果就是权重已经不再学习了(或学习缓慢)。对于输出神经元的偏移量也有相似的性质。
对于前面的层也有相似的性质。尤其注意(BP2)里的公式。这意味着如果神经元接近饱和有可能会很小。这反过来意味着所有输入到已饱和神经元的权重将学习的很慢。(如果足够大,能抵消的微小,那么这个推理将不成立。但我们讲的是通常情况)
总结一下我们学到的,权重将在下面几种情况下学习缓慢:输入神经元激活值很低;输出神经元已经饱和,也就是, 很低或很高的激活值。
这些性质非常出人意料。尽管如此,它们能改善我们脑子里神经网络学习的模型。而且,我们可以扭转这种推理。这四个基本等式是针对任意激活函数的,并不只是标准的Sigmoid函数(这是因为,正如我们所看到的,证明里没有使用的特殊属性)。因此我们可以使用这些等式来设计具有特定学习属性的激活函数。举个例子来加深题解,假设我们选择了一个(非Sigmoid)激活函数,让总是正数,并且永远不会接近0.这样就可以避免原本Sigmoid激活函数饱和后发生学习缓慢的问题。书的后面将看到这种改进类型激活函数的样品。记住(BP1)-(BP4)这四个等式,可以帮你解释为什么要尝试做这种改进,和它们所产生的影响。

问题
- 反向传播等式的另一种形式:我已经让反向传播等式使用了Hadamard积。这种形式可能会让没有用过Hadamard积的人感到不适。有一种基于传统矩阵乘法的方式可能会让一些读者找到灵感。
(1)等式(BP1)可以写成
这里的是一个对角线元素是值的方阵,其非对角线元素为0.注意这个矩阵和之间是传统的矩阵乘法。
(2)等式(BP2)可以写成
(3)通过结合(1)和(2)可以得到
对于那些习惯矩阵乘法的读者来说,这个等式可能比(BP1)和(BP2)理解起来更简单一些。关注(BP1)和(BP2)的原因在于这种方式实现数字化更快。