关于深度学习
我们的神经网络带来傲人成绩的同时,这个成绩又有几分神秘。权重和偏移量是在网络里被自动发现的。也就意味着我们不能马上解释网络是如何做到的。我们能找到一些途径来理解我们的网络分类手写体数字的原理吗?有了这些原理,我们能做的更好吗?
为了让这些问题更直白,假设几年之后神经网络领导了人工智能(AI)。我们能理解这种智能的网络是如何工作的吗?可能网络对我们是不透明的,我们不能理解它的权重和偏移量,因为是自动学习的。在AI研究的早期,人们希望通过努力构建一个AI来帮助我们理解智能背后的原理,可能就是人类大脑的功能。但也许结果将是最后我们即不能理解大脑,也不能理解人工智能的工作原理!
为了解决这些问题,让我们回忆一下我在本章开始时给出的人工神经元的解释,做为一种衡量证据的工具。假设我们想判断图片里是否是一张人类的脸:

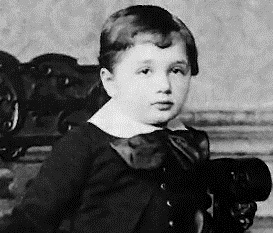

我们可能用和处理手写识别一样方式来处理这个问题——通过用图片的像素做为神经网络的输入,网络的输出指出“是一张脸”或“不是一张脸”。
让我们假设我们这样做,但不用学习算法。反而,我们尝试亲手设计一个网络,来选择合适的权重 和偏移量。我们该怎么做呢?暂且忘记整个神经网络,我们可以用一种启发式算法来分解这个问题至一些子问题:图片的左上方上有一只眼睛吗?右上方有一只眼睛吗?中间有鼻子吗?下面的中间有一张嘴吗?上面有头发吗?等等。
如果这些问题有几个是“是”,或即使只是“可能是”的话,那么我们可以推断这张图片像是一张脸。相反,如果大部分问题的答案是“不是”的话,那么这张图片可能不是一张脸。
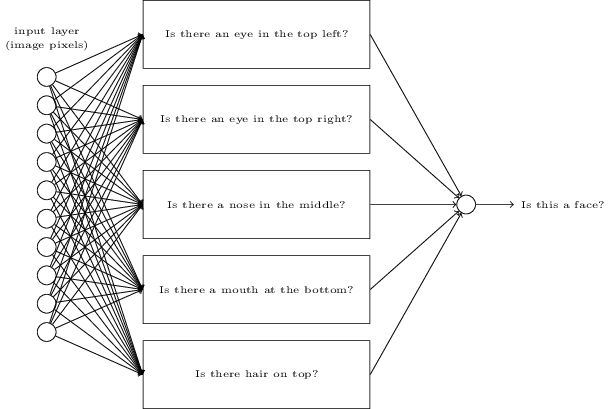
当然,这只是一个粗糙的启发式,有很多缺陷。可能这个人是一个秃子,所以就没有头发。或许我们只能看到一部分脸,或者脸有一个角度,所以有些面部特征就模糊了。尽管如此,这个启动发式表明如果我们能用神经网络解决这些子问题,那么或许我们可以通过整合这些子问题的网络,来构建一个面部识别神经网络。这里是一个可能的架构,里面的矩形表示这些子网络。注意这并不是现实里解决面部识别问题的方法;当然,它能帮助我们建立对网络功能的直观感觉。下面是这个结构:
子网络能被分解也是合理的。假设我们考虑这个问题:“左上方有一只眼睛吗?”可以被分解这样的问题:“有眉毛吗?”;"有睫毛吗?";“有虹膜吗?”;等等。当然这些问题实际上应该包含位置信息,就像这样——“眉毛是在左上方,并在虹膜上面吗?”——诸如此类的样子——但还是简单点好。网络要回答“左上方有一只眼睛吗?”这样的问题,现在可以被分解为:
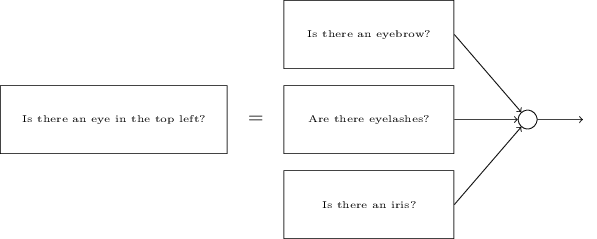
这些问题也可以通过多个层次进一步被分解。根本上,这些问题要让子网络可以在像素级别上轻松回答。这些问题可能例如这样,图片特别的位置上存不存在非常简单的形状。这样的问题可以通过单个神经元连接图片上的原生像素来解答。
最终的结果是网络将一个非常复杂的问题——图片是否展示了一张脸——分解成在像素级别上可以回答的简单问题。它通过一系列的的网络层来完成,前面的网络层回答非常简单和明确的关于输入图片的问题,后面的网络层建立一个更加复杂和抽象概念的层次。有这种多层结构的网络——两层或更多的隐含层——被称为深度神经网络(deep neural networks)。
当然,我还没说怎样去循环分解成子网络。在网络里手动设计权重和偏移量是不现实的。相反,我们希望使用学习算法,这样网络就可以自动地从训练数据中学习权重和偏移量,以及概念的层次。研究者们在1980至1990年代尝试使用随机梯度下降和反向传播算法来训练尝试网络。不幸的是,除了少数特定结构,他们没有多少运气。网络可以学习,但非常缓慢,在实践中经常因为太慢而没有用处。
从2006年起,一套技术被开发出来可以让深度神经网络进行学习。这些深度学习技术基于随机梯度下降和反向传播算法,但也加入了新的思想。这些技术已经让非常深(和庞大)的网络可以被训练——人们现在经常训练有5至10层隐含层的神经网络。事实证明在许多问题上它们的性能要比浅层神经网络好很多,如只有一个隐含层的网络。原因当然是建立一个复杂的概念层次是深度网络的能力。这有点像传统的编程语言使用模块化设计和抽象概念来建立复杂的计算机程序。比较一个深度网络和一个浅层网络有点像,让一个有能力让函数进行调用的编程语言,与一个没有这个能力的语言进行比较一样。抽象在神经网络和传统编程语言不太相同,但同样重要。