介绍卷积网络
在之前的章节中,我们教会了我们的神经网络去很好的识别了手写数字图像:
我们做这个时的网络,其相邻的网络层是全连接到另一层的。也就是说,每一个网络里的神经元是连接到相邻层的每个神经元的:
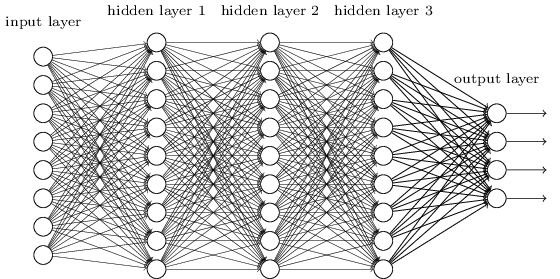
尤其是对输入图像是的每一像素,我们将像素的灰度编码成输入层中对应神经元的值。对于我们正在使用的像素的图片,这意味着我们的网络有()个输入神经元。然后我们训练网络的权重和偏移量,这样网络的输出将会——我们希望!——正确认出输入图片:'0', '1', '2', ..., '8', or '9'。
我们之前的网络很不错:我们使用来自MNIST手写数字数据集上的训练和测试数据集,已经得到一个超过98%的分类的准确率。但经过反思,使用全连通的网络做图片分类比较奇怪。原因是这样的网络架构没有考虑到图像的空间结构。例如,它对那些离的很远和靠的很近的像素是一样对待的。这种空间结构的概念必须要从训练数据中推断出来。但是,如果我们使用的是一个试图利用空间结构的架构,而不是一个空白的网络架构,那该怎么办呢?这一节说一下卷积神经网络【卷积神经网络的起源可以追溯到20世纪70年代。但是,建立卷积网络现代课题的是1998年的一篇开创性论文,"Gradient-based learning applied to document recognition", 作者 Yann LeCun, Léon Bottou, Yoshua Bengio, 和 Patrick Haffner. 此后,LeCun对卷积网络的术语做了有趣的评论:“在像卷积网络这样的模型中,[生物学中的]神经带来的灵感是少的。这就是为什么我称它们为'卷积网络'而不是'卷积神经网络',以及为什么我们称这些节点为'单元'而不是'神经元'”。尽管有这样的讨论,卷积网络使用了迄今我们已经学到的许多和神经网络一样的观点:诸如反向传播,梯度下降,正则化,非线性激活函数,等等。因此,我们将遵循惯例,将其视为神经网络的一种。我将交替地使用术语“卷积神经网络”和“卷积网络”。也将交替地使用术语“[人工]神经元”和“单元”】。这些网络使用一种特别的架构尤其适合来分类图片。使用这样的架构使得卷积网络可以训练的很快。这反过来又帮助我们训练深层的、多层次的网络,这些网络非常擅长对图像进行分类。今天,深度卷积网络或一些接近的变种被应用在大部分对图像识别的神经网络中。
卷积神经网络使用三个基本的思想:感受野,共享权重,和池化。让我们依次看下这些思想。
感受野:在之前展示的全连通层中,输入被描绘成一条神经元的竖线。在一个卷积网络中,最好将输入看成是一个的神经元正方形,它们的值对应我们输入像素的灰度:

像往常一样,我们会把输入像素连到一个隐含神经元的层。但我们不会连每一个输入像素到每个隐含神经元上。相反,我们只在输入图像上很小的局部区域中做连接。
更准确的说,第一个隐含层的每个神经元将连到一个输入神经元的小区域上,例如,比方说一个的区域对应个输入像素。所以,对于一特定隐含神经元,可能有像这样的连接:
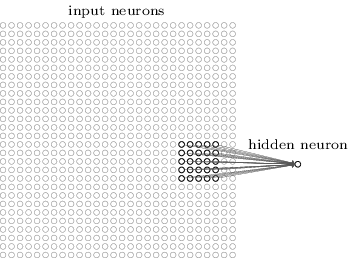
这个输入图像中的区域被称为隐含神经元的感受野。它是输入像素上的一个小窗口。每个连接学习一个权重。并且隐含神经元也会学习一个整体的偏移量。你可以理解成这个特定的隐含神经元学习去分析其他特定的感受野。
然后我们滑动这个感受野穿过整个输入图片。对每个感受野,第一个隐含层有一个不同的隐含神经元。为了作具体说明,让我们从左上角的一个感受野开始:

然后我们向右滑动感受野一个像素(也就是,一个神经元),来连接第二个隐含神经元:

依此类推,构成了第一个隐含层。注意如果我们的输入图像为,感受野为,那么在隐含层里将有个神经元。这是因为我们可以在碰到图片的最右边(或最下边)之前,只移动感受野穿过个神经元(或下降个神经元)。
我刚展示了感受野一次移动一个像素。实事上,有时会使用不同的步幅长度。例如,我们可以向右(或下)移动感受野个像素,其中我们说所使用的步幅长度为。在这一章里我们主要还是维持步幅为,但还是值得了解人们有时会用不同的步幅长度来试验【正如前面几章所做的,如果我们想尝试不同的步幅,那么我们可以使用验证数据来挑选出最佳性能的步幅。更多细节可以看前面的讨论,怎样在神经网络里挑选超参数。同样的方法可以来挑选感受野的大小——当然,用的感受野没有什么特别的。一般来说,当输入图像比的MNIST图像要大很多时,大的感受野趋向于更有帮助一些。】。
共享权重和偏移量:我说过每个隐含神经元有一个偏移量和的权重连接至他的感受野上。我还没有提到的是我们对这个隐含神经元将用相同的权重和偏移量。换句话说,对第个隐含神经元,输出是:
这里,是神经元的激活函数——假定是前面章节里用过的sigmoid函数。是偏移量的共享值。是一个的共享权重数组。最后,我们用来表示在位置上的输入激活值。
这就意味着第一个隐含层里的所有神经元检测到的是完全一样的特征【我还不没有准确定义特征的概念。通俗地讲,可以把一个隐含神经元检测出的特征看成是一种会激活神经元的输入模式;例如,它可能是图像的边缘,或是其他类型的形状。】,只是在输入图像的不同地方而以。为了明白为什么要这样做,假设权重和偏移量是隐含神经元可以辨认的,比方说,一个垂直边缘在一个特定的感受野里。这种能力也可以用在图像的其它地方。所以它可以用相同的特征来检测图像的所有地方。用较抽象的术语来说,卷积网络很适合图像的平移不变性:把一张猫的图片挪一挪,它仍是一张猫的图像【实事上,对我们已经学过的MNIST数字分类问题来说,图像是居中和统一大小的。所以可以讲,MNIST比“世上”图片的平移不变性要小。像边和角这样的特征还是可以用到大部分输入空间中】。
出于这种原因,我们有时称输入层到隐含层的映射为一特征映射。我们称定义在特征映射里的权重为共享权重。称定义在特征映射里的偏移量为共享偏移量。这些共享权重和偏移量经常被称为定义一个kernel或filter。人们有时会在文献里以稍微不同的方式使用这些术语,因此我就不再具体展开了;不如一会儿我们来看一些具体的例子。
目前我所描述的网络架构只能检测一种局部特征类型。为了实现图像识别我们还需要更多的特征映射。所以一个完整的卷积层由多个不同的特征映射组成:
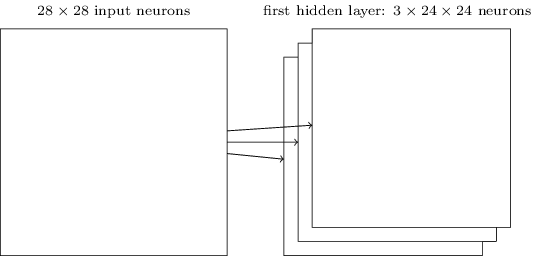
在展示的例子中,有3个特征映射。每个特征映射定义了一组的共享权重和一个单独的共享偏移量。这样网络就可以检测三种不同类型的特征,每个特殊可以通过对整个图像进行检测得出。
我只展示了3个特征映射是为了让上面图示简洁一些。然而实践上卷积网络可能用很多(或许非常多)的特征映射。早期卷积网络之一的LeNet-5,使用了6个特征映射,每个关联了一个的感受野来识别MNIST数字。所以上面的插图很接近LeNet-5。这一章后面我们开发的例子中,将用20和40个特征映射的卷积层。让我们快速浏览下学到的一些特征【特征映射插图来自我们最终训练的卷积网络,可以看这里】:

这20张图片相当于20个不同的特征映射(或filters或kernels)。每个映射代表一块的图片,相当于感受野里的权重。白色块意味着一个小(通常是有更多负的)一些的权重,因此特征映射表达对应的输入像素会少一些。深色块意味着一个较大的权重,所以特征映射表达对应的输入像素要更多一些。非常不严谨的讲,上面的图片展示了卷积层表达特征的类型。
所以我们可以从这些特征映射里推断出什么呢?很明显这里的空间结构已经超越了我们的预期中杂乱无章:许多特征有清晰的明和暗的子区域。这表示我们的网络是真的学习到了关于空间结构的东西。然而,除此这外,很难看出这些特征学会了检测什么。当然,我们还没有学习传统图像识别方法中用到的(比如说)Gabor filter。实事上,现在有很多成果能更好的理解卷积网络的特征学到的东西。如果你对这方面感兴趣,我建议你看下这篇论文Visualizing and Understanding Convolutional Networks ,作者 Matthew Zeiler 和 Rob Fergus (2013).
共享权重和偏移量最大的好处就是大大减少了卷积网络所包含参数的数量。对每个特征映射我们需要个共享权重,加一个单独的共享偏移量。所以每个特征映射需要26个参数。如果我们有20个特征映射,就需要在卷积层定义共个参数。作为对比,假设第一层是全连通的,有个输入神经元,还有一个相对适度的30个隐含神经元,我们在这本书前面的许多例子都这样用。这样总共有个权重,加一个额外的个偏移量,总计个参数。换句话说,全连通层将比卷积层参数的数目多40倍。
当然,我们不用真的直接比较参数的数目,因为这两个模型本质上是不同的。但直观上讲,通过应用卷积层的平移不变性,可以用较少的参数数量,达到和全连通模型相同的性能。这转而将会使卷积模型训练的更快,最终将帮我们用卷积层构建深度网络。
顺便说一下,卷积这个名称来自公式(125)的操作,它有时被称为卷积。更详细一点,人们有时将那个方程写为,这里的表示来自一个特征映射的一组输出激活值,表示一组输入激活值,被称为一个卷积操作。我们不打算深入做卷积在数学上的应用,所以你不必太担心这一关系。但这至少值得了解其名称的由来。
池化:除了描述的卷积层外,卷积神经网络还包括池化层。池化层通常紧跟在卷积层后面。池化层就是来简化从卷积层到输出层间信息的。具体地说就是,池化层从卷积层获取每个特征映射【这里的术语用的很随意。尤其是,我用“特征映射”不是指卷积层的计算函数,而是指从这些层输出的隐含神经元的激活值。这种对命名法的轻微滥用在研究文献中是很常见的。】的输出,并准确一个浓缩的特征映射。例如,池化层里的每个单元可能囊括了上一层里区域的神经元。一个更具体的例子,一个普遍的池化层技术被称为最大池化层(max-pooling)。在最大池化层里,一个池化单元像下面图示的插图一样,简化输出为输入区域里的最大激活值:

注意因为我们有来自卷积层个神经元的输出,后面的池化层将有个神经元。
像上面提到的,卷积层通常包含多个特征映射。我们需要分别对每个特征映射应用最大池化技术。所以如果有三个特征映射,合并后的卷积和最大池化层会像:
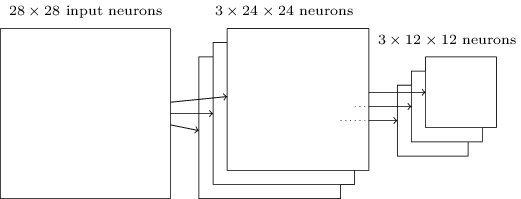
我们可以把最大池化看成是一种网络询问图像区域是否发现给定特征的方式。然后它扔掉了确切的位置信息。凭直觉,一旦发现了特征,它的确切位置并没有其相对于其他特征的大概位置重要。最大的收益就是出现了许多更少的池化特征,因此这帮助减少了后面层所需的参数数量。
最大池化并不是池化使用的唯一技术。另一个普通方法被称为L2池化。这个不是取区域神经元的最大激活值,而是取区域内激活值平方和的平方根。虽然细节上有所不同,直观上和最大池化很相似:L2池化是一种从卷积层压缩信息的方式。实践上,这两种技术被应用的都很广泛。有时人们会用其他类型的池化操作。如果你想真正的优化性能,你可以用验证数据比较不同的池化方式,来挑选出效果最好的方法。但我们不打算对此类细节上的优化类型上费太多笔墨。
整合:我们现在可以将这些想法整合起来,构成一个完整的卷积神经网络。它和我们之前看到的架构很相似,但多了一个有10个输出神经元的输出层,对应MNIST数字的10个可能值('0', '1', '2', 等)
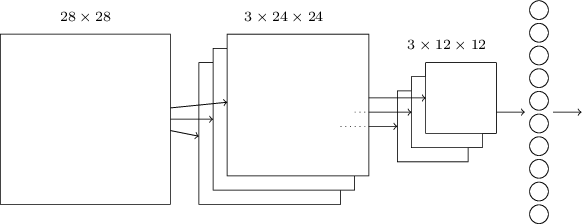
网络从个输入神经元开始,用来对MNIST图像的像素灰度进行编码。后面跟着一个卷积层,和一个的感受野和3个特征映射。形成了一个有隐含特征神经元的层。下一步是一个最大池化层,应用的区域到3个特征映射的每个。形成 了一个有个隐含特征神经元的层。
网络的最后一层是一个全连通层。也就是说,自最大池化层的每个神经元都连到层中10个输出神经元的每一个输出神经元。这种全连通的架构和我们前面章节中用的一样。尽管这样,还是要注意在上面图示里,我为了简洁用了一个单独的箭头,而没有展示出所有连接。当然你可以很简单的想象出这些连接。
这种卷积架构和之前章节使用的架构很不同。但背景思想是相似的:网络由许多简单单元组成,它们的行为由权重和偏移量决定。而且整体目标是一致的:通过用训练数据训练网络的权重和偏移量,这样网络就可以有效的分类输入数字。
特别的,和之前书中一样,我们将用随机梯度下降和反向传播法来训练我们的网络。这基本上和前面几章完全一样。尽管这样,我们还是需要对反向传播程序做一点修改。因为我们之前推导的反向传播算法是对应全连通层的网络的。幸运的是只需要简单修改卷积和最大池化层的推导就可以了。如果你想了解其中的细节,我邀请你通过做下面的问题来展开。提醒一下,解决这个问题要花不少时间,除非你真的消化了之前反向传播的推导过程(这样就会容易很多)。
问题
- 卷积网络中的反向传播:全连接层网络里反向传播的核心方程为(BP1)-(BP4)(连接)。假设和上面讨论的网络一样,包含一个卷积层,一个最大池化层,和一个全连接输出层。那反向传播的方程需要做怎样的修改?