过拟合和正规化
诺贝尔奖获得者物理学家Enrico Fermi被问及他对一个数学模型的看法,一些同事认为这个模型可以解决一个重要的未解决的物理问题。这个模型与实验结果非常吻合,但Fermi却表示怀疑。“4”才是答案。Fermi回答说【引号来自Freeman Dyson一部非常好的文章,他是其中一个提出缺陷模型的人。一只四参数的大象可以在这里找到。】:“我记得我的朋友Johnny von Neumann曾说过,有4个参数我可以匹配一头大象,如果有5个我可以让它摆动鼻子”。
当然,问题的关键在于,有大量自由参数的模型可以描述各种各样的现象。即使这个模型与现实很吻合,也不能说它是一个好模型。它可能只是意味着模型有足够的自由度,可以描述几乎所有给定大小的数据集,但并没有对底层现象作真实深入的理解。这样的话,模型在已有数据上表现很好,但推广到新环境就会失败。对模型的真正测试是在它没有接触过的环境下做出预测的能力。
Fermi和von Neumann对四个参数的模型表示怀疑。我们分类MNIST数字的网络有30个隐藏层近24,000个参数!这是很多个参数。我们100个隐藏层的网络有近80,000个参数,并且最先进的深度神经网络有时包含百万甚至上亿个参数。我们可以相信它们的结果吗?
通过构造一个场景,让我们的网络泛化到新场景时表现不好,来快速显示这个问题。使用30个隐含神经元的网络,它有23.860个参数。但我们不训练所有的50,000个MNIST图片。相反,我们只使用前1,000个训练图片。使用这个有限的集合泛化问题将变得很明显。我们将用和以前相似的方式来训练,使用交叉熵成本函数,学习率为,最小批次为10。尽管这样,我们将训练400代,比较之前多很多,因为我们没有用太多的训练样品。让我们用network2来看下成本函数的变化:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data[:1000], 400, 10, 0.5, evaluation_data=test_data,
... monitor_evaluation_accuracy=True, monitor_training_cost=True)
用输出结果可以画出网络学习成本变化的趋势【这个和下面的4个图是用overfitting.py程序生成的】:
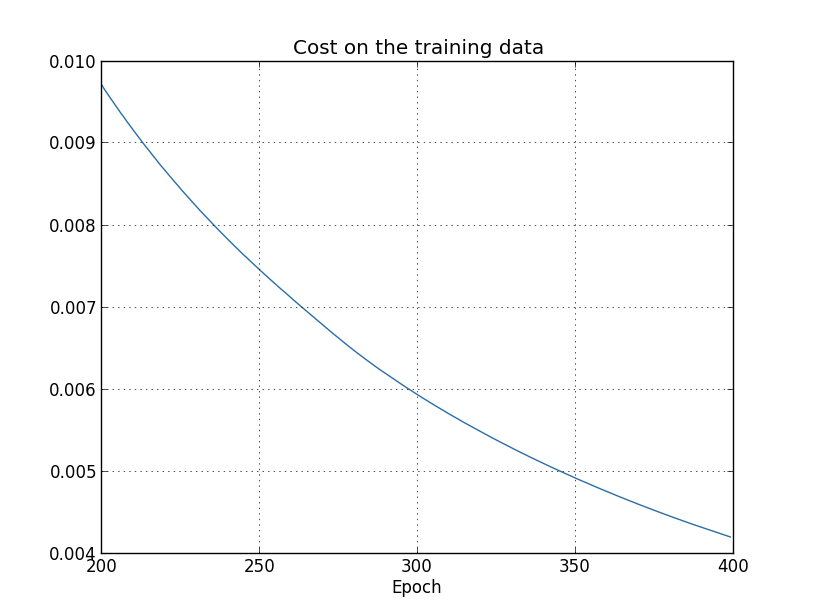
这看上去很不错,成本在平滑的下降,就像我们期望的一样。注意这里只展示了200至399代。这给我们一个近距离观察学习后期的画面,就像我们将看到的,它的表现将变得很有意思。
现在看一下分类准确率在测试数据上随时间变化的趋势:
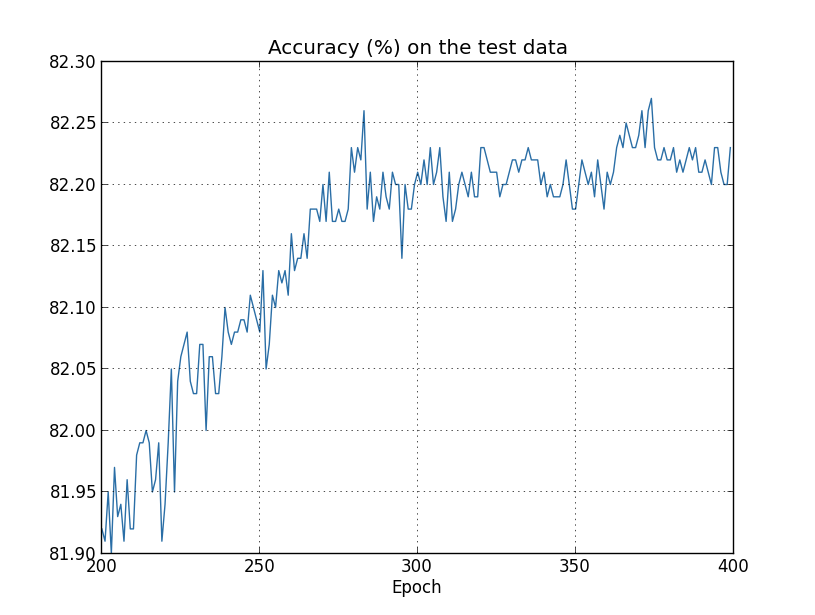
又一次放大了很多倍。在前面的200代(没有显示出来)准确率上升至不到82%。然后学习开始放缓。最后在280左右分类准确率达到最佳就停止提升。后面的部分仅仅是在280代准确率值的附近作很小的随机波动。对比之前的图片,与训练成本相关的成本继续平滑下降。如果我们只看成本,看上去我们的模型仍然在变“好”。 但测试准确率的结果显示这个改善只是一个假象。就像Fermi不喜欢的模型一样,我们的网络在学习280代后就不再泛化测试数据了。因此它是无效的学习。我们将超过280代的部分称为网络是过拟合的或训练过度的。
你可能会怀疑问题是不是因为成本用的是训练数据,对照的分类准确率用的是测试数据。换句话说,问题可能是在对比一个苹果和橘子。那如果比较训练数据上成本和测试数据上的成本,所以我们就在比较相似的参照物?或者也许我们应该在训练数据和测试数据上都比较分类准确率?实事上,无论我们如何比较,基本上相同的现象都会出现。尽管细节上会有所改变。举例来说,让我们看下测试数据上的成本:
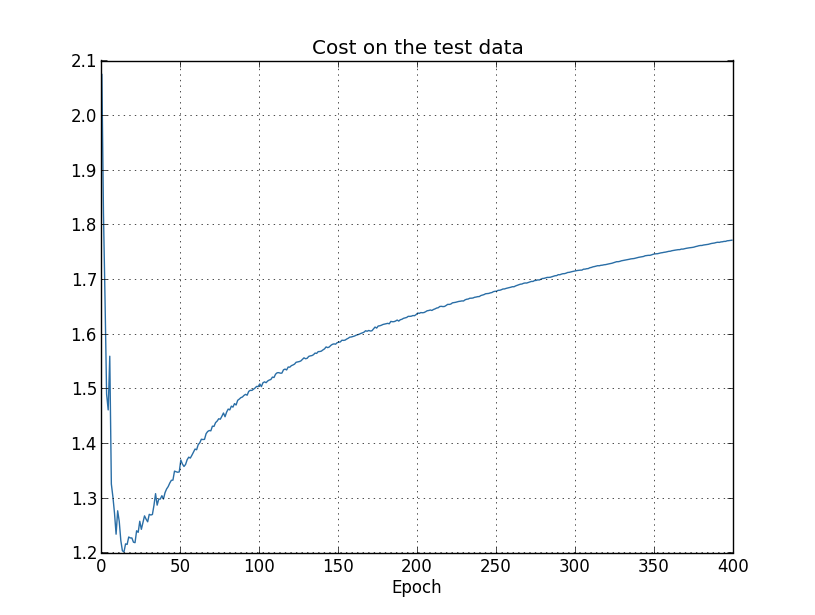
可以看到测试数据上的成本提升直到15代左右,但在后面它实际上开始变糟,即使训练数据上的成本是继续变好的。这是我们模型过拟合的别一个标志。然而这就出了一个难题,究竟是15代这个点还是280代是学习进入过拟合的临界点?从实用角度来看,我们真正应该关心的是测试数据上分类准确率的提升,而测试数据上的成本仅仅是来替代分类准确率。因此在我们的神经网络中把280代之做为学习进入过拟合状态的临界点更有意义一些。
过拟合的另一个标志是看训练数据上的分类准确率:
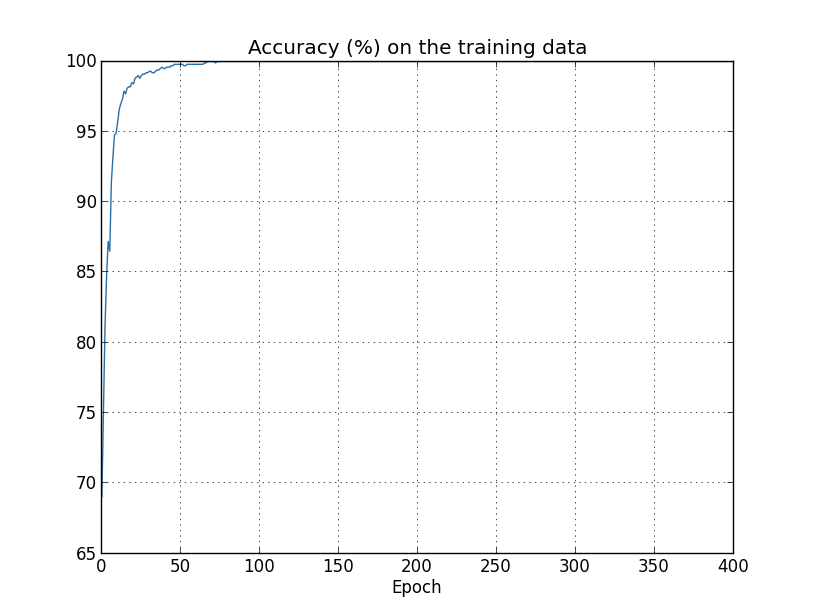
准确率一中上涨到100%。也就是说,我们的网络正确分类了所有1,000张训练图片!同时我们的测试准确率最高也就82.27%。所以我们的网络真正学习到是训练集的独特性,并没有识别平常的数字。这几乎就像是我们的网络仅仅是记住了训练集,没有足够好的理解数字来泛化到测试集上。
过拟合是神经网络一个主要问题。尤其是在现代经常有着大量权重和偏移量的网络中。为了让学习更有效,我们需要一个能检测发生过拟合的方法,这样我们就不用过度训练了。并且我们希望能有技术来减小过拟合带来的影响。
检测过拟合最直接的方式是使用上面的方法,像我们训练网络一样,跟踪测试数据集上的准确率。如果我们看到测试数据集上的准确率不再提升了,然后我们就应该停止训练。当然,严格来说,这不是标志过拟合的必要条件。有可能测试数据和训练数据上的准确率在同一时刻都停止提升了。不过采用这个策略将防止过拟合的发生。
事实上我们将用这个策略的一个变种。回想一下,当然加载MNIST数据的时候,我们加载了三个数据集:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
到目前为止我使用了trainingdata和test_data,省略了validation_data。 validation_data有10,000张数据图片,它不同于MNIST训练集的50,000图片,也不同于MNIST测试集的10,000张图片。我们将使用validation_data,而不是test_data来防止过拟合。为此,我们将使用与上面描述的test_data相同的策略。也就是说,我们将在每一代的最后用validation_data来计算分类准确率。一但validation_data上的分类准确率饱和了,就停止训练。这种策略被称为提前停止(early stopping)_。当然,在实际中我们并不能立即知道准确率什么时候饱和。替代的,我们会继续训练直到确认准确率已经饱和了。【这需要一些确定什么时候停止的判断。在之间的图片中我认为在280代这个点上准确率饱和了。神经网络在继续提升前,有时会平缓一段时间。即使再学习400代后才会出现提升,我也不会感到惊讶,尽管未来的每一次提升幅度都很小。所以对提前停止来说可以采取或多或少的激进的策略。】
为什么使用validation_data来防止过拟合,而不是test_data?实事上,使用validation_data来评估不同初始选择的超参数是一种更广泛的的策略,比如训练多少代、学习率和更佳的网络结构等等。我们用这样的评估方式来寻找和设置较好的超参数。的确,虽然我至到现在都没有提及,本书之前的超参数部分是用这种方式选择的。(后面有更多介绍)
当然,那并没有回答为什么用validationdata来防止过拟合比test_data好。相反,它替换成一个更广泛的问题,为什么用validation_data来设置较好的超参数比test_data好?为了理解为什么,考虑下当设置超参数时我们喜欢尝试不同的超参数。如果我们基于test_data的评估来设置超参数,可能会让超参数最终过拟合test_data。也就是说,可能最终找到的超参数只是适应于独特的test_data,但网络不能泛化到其他数据集。防止这种情况的出现就是使用validation_data来决定超参数。然后,一旦我们找到了我们想要的超参数,用test_data来做一次最终的准确率评估。那让我们相信基于test_data的结果是能正确衡量网络泛化能力的。另一方面,你可以将验证数据当成是一种帮我们学习较好超参数的训练数据类型。这种寻找较好超参数的方式有时被称为留出(hold out)_法,因为validation_data是与training_data分开或“留出”的。
当前的实践中,在test_data上评估了性能后,仍有可能会改变想法,想试试另一种方式——也许是一个不同的网络结构——这就要再去找一个新的超参数集。如果这样做的话,是否也存在最终过拟合test_data的危险?是否需要一个可能无限回退的数据集,让我们可以相信得到的结果是会泛化的?完全解决这个问题是一个深刻和困难的问题。但对于我们的实际目的来说,完全不必太在意这个问题。相反,我们会直接 用最基本的留出法,基于training_data,validation_data和test_data,就像上面描述的那样。
我们一直看到的过拟合是使用1,000个训练图片的情况。当用50,000张图片的全训练集的话又会怎么样呢?我们用一样的参数(30个隐藏神经元、0.5的学习率,最小批次大小为10),但训练所有50,000张图片30代。这里是展示在训练数据和测试数据上分类准确率结果的图片。注意这里我用的是测试数据而不是验证数据,为了能和之间的图片做比较。
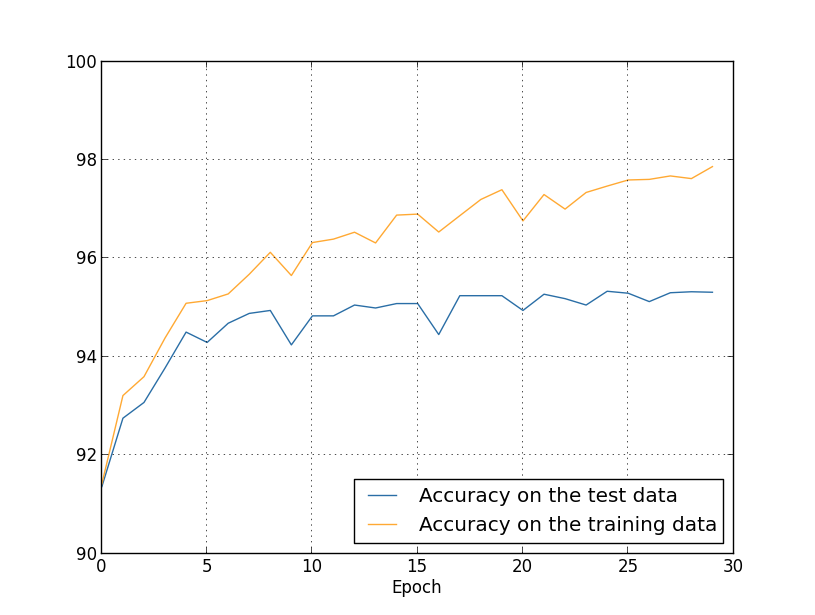
正如你所看到的,在测试和训练数据上的准确率要比用1,000个训练样本时之间紧密的多。尤其是,训练数据上的最好分类准确率97.86%只比测试数据上的最高准确率95.33%只高2.53%。这与之前相比有17.73%的差距!过拟合现象仍然存在,但已经减少了很多。网络从训练数据到测试数据要泛化的更好。通常,减小过拟合的一个最好方式就是增加训练数据的大小。有了足够的数据,即使是非常庞大的网络也很难过拟合。不幸的是,训练数据是很昂贵或者很难获取,所以这并不是一个实际的选择。